One of our customers was upgrading their intranet from SP2010 to 2013, and wanted help improving their document management solution simultaneously. Their current solution already had a lot of document templates, and since we wanted to merge some of the libraries having different templates, we were looking at a situation of having libraries with perhaps 30-50 templates, which in SharePoint means 30-50 content types. Not only would this be a pain to maintain, it also makes it much harder for users to use the templates. And let’s face it, managing document templates in SharePoint is already an awful experience, even with just a few templates to manage. In this case, as in most, the metadata from SharePoint had to be visible in the documents created using the templates as well. That meant having quick parts in the templates with a connection to the fields in the SharePoint library. So, in a conversation with the customer, one of them asked if we couldn’t simply put the templates in Word instead. My immediate reaction was “Hmm… no… i don’t think so. I don’t think the connection to SharePoint will be maintained”. But then I thought about it and figured it just might work. If the template was stored in a SharePoint library, the correct quick parts could perhaps be added and work anyway. So I did some searching and came up with the following solution:
- Put the documents that should be used as templates in a document library in SharePoint
- Set the Workgroup templates property in MS Word to the address of the SharePoint template library
In other words, new documents aren’t created from the SharePoint library at all. Instead the user can create new documents directly from word, which is an improvement in my opinion (though I would prefer if you could still create documents from SP as well). The Workgroup templates property in Word allows users to point to a folder, making all the documents in that folder appear as custom templates in Word. The problem was that you’re not allowed to set the Workgroup templates property to a web address. I did some searching, and found a few posts on how to work around this. What you need to do is:
- Map a network drive to the address of the SharePoint library
- Set the Workgroup templates property in MS Word to another network drive (not the one you just created)
- Open regedit and modify the property to point to your own network drive
After performing these steps, the files stored in the SharePoint library can be used as templates in word, with working quick parts, and you won’t even need to open SharePoint to create documents anymore. Note: This works in both SharePoint on-premises, and SharePoint Online!
Ok, so how do we do this?
1. Map a network drive to a SharePoint library
There are plenty of examples out there on how to do this. Here is the MS one: https://support.microsoft.com/en-us/kb/2616712?wa=wsignin1.0
- Make sure the site with the document library is added to your list of Trusted Sites.
- If using SharePoint Online, log into your tenancy, and make sure to remember the credentials.
- Right-click Computer and choose “Map network drive…” in the menu.
- In the Map Network Drive dialog, enter the following. Drive: Choose a Drive to map it to. I like S: as in SharePoint. =) Folder: Paste the URL to the document library
- Click Finish
Windows explorer should now be opened automatically, showing you the contents of the library. 
2. Set the Workgroup templates property in MS Word
The next thing we need to do is set the Workgroup templates property in MS Word. This will make the given location be used as a folder for custom document templates. I am using Word 2013 in this example. But it should work for 2007 and 2010 as well, even if the paths may vary.
- Open MS Word
- Go to File –> Options –> Advanced (scroll to the bottom) and click the “File Locations…” button.
- Modify the Workgroup templates property and set it to a non-web address location. I set it to D: for example (see image)
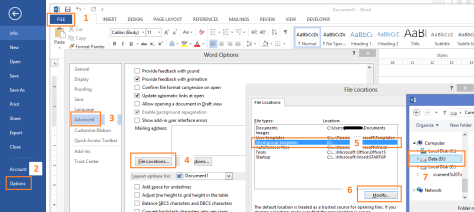
- Confirm all the dialogs and close Word.

3. Open regedit and modify the property
- Open up the registry editor (press the windows key, type “regedit”, press enter)
- Go to HKEY_CURRENT_USER/Software/Microsoft/Office/15.0/Common/General Note: Replace “15.0” with your current office version.
- Modify the “SharedTemplates” property and set it to the drive of your SharePoint library, in my case S:
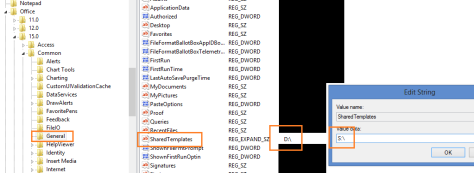
- Confirm the dialog and close the registry editor.

4. Create a new document using your new template
And now you are done, ready to use the documents stored in the library as templates!
- Open Word and go to the New screen
- Click the Custom tab, and you will see a folder named “S:” (or whichever drive you mapped the library to)
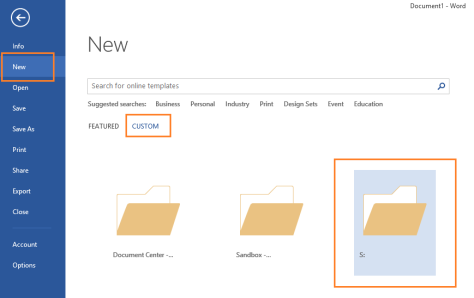
- Open the S: folder to see all the documents stored in the library. Just click the one you want to use as a template.

- Word will now copy the document from SharePoint and create a new file for you, with SharePoint field references working perfectly.



Benefits over regular SharePoint document templates
Easier to update templates. To edit the templates, you just need to edit the documents stored in the template library, rather than edit the template file connected to a content type, saving you a lot time, especially when adding/changing quick parts in the template. Create documents from Word, instead of SharePoint. Word is the program you use to edit documents, so why should I have to go to SharePoint to create a new one? Wouldn’t it be easier if I could create a new document from a template directly in Word? Yes it would. It would simplify the process greatly. Separation between Content Types and Template. Having a 1-to-1 relationship between Content Types and Templates is a system design mistake of epic proportions, and one of the reasons you cannot create a great document management system in SharePoint without customizations. Separating the two is a major win, enabling you to have a great number of templates without adding unnecessary complexity.
Limitations and drawbacks
Single Site Collection. This solution will ONLY WORK ON A SINGLE SITE COLLECTION! The templates will need to be stored on a library on the same site collection were the new documents will be saved. It can be on different web sites, but save it on another site collection and the fields won’t update inside the document, even if the content type is distributed through a content type hub. This means that the users need to know where to save the documents if they should work as expected. This basically means that you cannot have a document management system (DMS) consisting of several site collections, which you shouldn’t want to anyways. But this puts a limit to scalability. You can use archiving to keep your DMS site collection below the recommended levels, but it’s still more limited. There may be a way around this by ensuring that the fields SourceID and internalName attributes are consistant between site collections, but I haven’t tested it yet. I hope you give this a try. It’s a working (although not great) way of separating Content Types and Templates, which is something MS should have done a looong time ago.





